
RAG Architecture relies on vector databases to efficiently store, retrieve, and manage high-dimensional embeddings. As RAG-based systems gain popularity, selecting the right database is crucial for ensuring fast, accurate, and secure information retrieval. In this guide, we’ll explore and compare several leading vector databases across key performance factors.
Key Parameters for Comparison
When evaluating vector databases for a RAG system, consider the following key parameters:
Performance & Speed:
How fast can the database index and query large volumes of high-dimensional data?
Scalability:
Can the solution handle growth in data volume and concurrent queries?
Integration & Flexibility:
How easily does the database integrate with existing infrastructure and support various data types?
Accuracy & Relevance:
What similarity search methods are available, and how customizable are they?
Security & Compliance:
What measures are in place to protect sensitive data?
Cost & Operational Overhead:
How do pricing models and maintenance needs compare?
Comparative Analysis of Popular Vector Databases
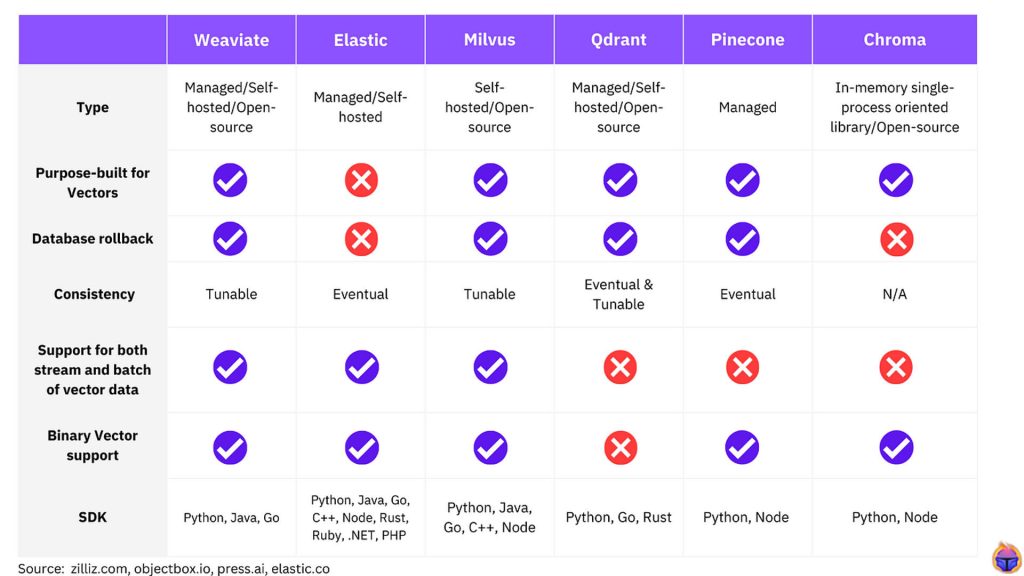
Below is a comparison of some leading options: Pinecone, Weaviate, Milvus, FAISS, and OpenSearch.
1. Pinecone
Performance & Speed:
Optimized for real-time, low-latency queries with advanced indexing algorithms.
Scalability:
Offers seamless scaling through a fully managed, cloud-based architecture.
Integration & Flexibility:
Provides robust APIs and integrates well with popular ML frameworks.
Accuracy & Relevance:
Uses state-of-the-art similarity measures; tuning parameters is straightforward.
Security & Compliance:
Implements strong security protocols and data encryption.
Cost & Operational Overhead:
Managed service with a subscription-based pricing model; minimal overhead.
2. Weaviate
Performance & Speed:
Delivers efficient vector search with support for various indexing options.
Scalability:
Designed to scale horizontally; well-suited for enterprise-level deployments.
Integration & Flexibility:
Open-source with modular architecture and flexible schema design.
Accuracy & Relevance:
Customizable similarity measures; supports hybrid search (combining vector and keyword search).
Security & Compliance:
Provides enterprise-grade security features including role-based access control.
Cost & Operational Overhead:
Open-source nature allows cost efficiency; however, self-hosting may add operational complexity.
3. Milvus
Performance & Speed:
Excels in large-scale similarity search and leverages GPU acceleration.
Scalability:
Built for massive datasets with strong support for distributed deployment.
Integration & Flexibility:
Integrates with multiple frameworks and data processing pipelines.
Accuracy & Relevance:
Supports various distance metrics and fine-tuning for specialized tasks.
Security & Compliance:
Implements robust security protocols; enterprise-ready.
Cost & Operational Overhead:
Offers both open-source and managed service options; GPU-based acceleration might increase costs.
4. FAISS (Facebook AI Similarity Search)

Performance & Speed:
Known for high-speed search in high-dimensional spaces; excellent for research and prototyping.
Scalability:
Highly efficient on single machines, but scaling out requires additional custom integration.
Integration & Flexibility:
Library-focused solution; requires more effort to integrate into production environments.
Accuracy & Relevance:
Provides state-of-the-art algorithms for similarity search; parameter tuning is highly customizable.
Security & Compliance:
Security features depend on the overall infrastructure since FAISS is primarily a library.
Cost & Operational Overhead:
Free and open-source, but may demand significant engineering effort to operationalize at scale.
5. OpenSearch
Performance & Speed:
Originally a full-text search engine, OpenSearch has evolved to support vector search via plugins (e.g., kNN plugin). While it may not match the performance of specialized vector databases in pure vector search benchmarks, it offers competitive speeds for hybrid search workloads.
Scalability:
Built on a distributed architecture, it can scale horizontally and is suitable for handling large datasets.
Integration & Flexibility:
Integrates natively with the Elasticsearch ecosystem and provides RESTful APIs. Ideal for use cases requiring both keyword and vector searches.
Accuracy & Relevance:
Offers vector search capabilities alongside traditional text search, which can be beneficial for combined use cases. Customizable similarity metrics are available, though tuning might be less straightforward than dedicated vector DBs.
Security & Compliance:
Provides enterprise security features, including encryption and fine-grained access control, similar to other enterprise search solutions.
Cost & Operational Overhead:
Open-source with options for managed services; might be a cost-effective option if you already use it for full-text search.
When to Choose Each Option
Pinecone and Milvus are excellent for teams prioritizing speed and scalability, especially when working with massive, high-dimensional datasets in a production environment.
Weaviate offers a flexible, open-source alternative that shines in environments requiring modularity and hybrid search capabilities.
FAISS is ideal for research or prototyping phases where rapid experimentation and state-of-the-art performance are crucial, albeit with more manual integration.
OpenSearch stands out if your use case benefits from combining traditional full-text search with vector search, or if you are already invested in the OpenSearch/Elasticsearch ecosystem and want to extend its capabilities.
Conclusion
Choosing the right vector database for your RAG architecture involves balancing performance, scalability, integration capabilities, accuracy, security, and cost. By comparing options like Pinecone, Weaviate, Milvus, FAISS, and OpenSearch, you can select a solution tailored to your specific needs. Whether you prioritise dedicated vector search speed or the benefits of a hybrid search engine, the right choice will empower your RAG system to deliver fast, accurate, and contextually rich results.
FAQ
Question: What is a vector database, and why is it important in RAG?
Answer: A vector database stores high-dimensional embedding vectors, enabling efficient similarity search. This makes it essential for Retrieval-Augmented Generation (RAG) workflows where embedding-based document retrieval enhances LLM responses.
Question: How does RAG architecture work with vector databases?
Answer: RAG uses embeddings of user queries to retrieve relevant documents from a vector database, then feeds those documents into an LLM to generate accurate answers. The vector DB handles retrieval, while the LLM handles generation.
Question: What are the key components of a scalable RAG system?
Answer: A robust RAG architecture includes a vector database, an embedding model, a document store, and an LLM inference engine. Proper orchestration between these ensures fast, accurate, and secure outputs.
Question: Which open-source vector databases are highlighted in the blog?
Answer: The blog covers options like Pinecone, Weaviate, Milvus, and Vespa, evaluating them on performance, scalability, features, and integrations for RAG applications.
Question: How do I choose the best vector DB for my use case?
Answer: Consider factors like query throughput, latency, cost, support for hybrid search (vector + keyword), and ease of integration with your LLM pipeline and cloud environment.
Question: What role do embeddings play in a vector-powered RAG system?
Answer: Embeddings convert raw text into numerical vectors that represent semantic meaning. Their quality directly affects retrieval relevance, influencing the accuracy of generated answers.
Question: Can I combine keyword search with vector search?
Answer: Yes, hybrid search combines vector similarity with keyword matching to improve precision, filtering results by metadata or relevance to meet advanced query requirements.
Question: How is data updated or added in a live RAG-enabled application?
Answer: New documents are embedded and added to the vector DB in real-time or via batch pipelines, ensuring the retrieval system stays up-to-date with fresh content.
Question: How do you scale vector databases for production-grade RAG?
Answer: Production scaling involves sharding vectors, replicating nodes, tuning indexing parameters, and selecting optimized hardware, all supported by mature vector DB platforms.
Question: What are common pitfalls when implementing RAG architectures?
Answer: Pitfalls include embedding mismatches, poor retrieval due to sparse vectors, index explosion, and ignoring metadata filtering. The blog emphasizes best practices to mitigate these risks.
Question: How do I evaluate the performance of my RAG system?
Answer: Use metrics like Retrieval Accuracy, Latency, Recall@K, and overall LLM answer quality. Regular benchmarking guides improvements in embeddings, retriever configurations, and LLM prompts.
For expert guidance in implementing scalable AI infrastructure and vector search technologies, consider partnering with Dev Centre House Ireland, a leader in delivering high-performance backend and AI solutions.